Por Qué Evaluar Agentes¶
En el desarrollo de software tradicional, las pruebas unitarias y las pruebas de integración proporcionan confianza de que el código funciona como se espera y permanece estable a través de los cambios. Estas pruebas proporcionan una señal clara de "pasa/falla", guiando el desarrollo posterior. Sin embargo, los agentes LLM introducen un nivel de variabilidad que hace que los enfoques de prueba tradicionales sean insuficientes.
Debido a la naturaleza probabilística de los modelos, las aserciones determinísticas de "pasa/falla" a menudo no son adecuadas para evaluar el rendimiento del agente. En cambio, necesitamos evaluaciones cualitativas tanto de la salida final como de la trayectoria del agente - la secuencia de pasos tomados para alcanzar la solución. Esto implica evaluar la calidad de las decisiones del agente, su proceso de razonamiento y el resultado final.
Esto puede parecer mucho trabajo adicional para configurar, pero la inversión de automatizar las evaluaciones se amortiza rápidamente. Si tienes la intención de progresar más allá del prototipo, esta es una práctica recomendada altamente recomendada.
Preparándose para las Evaluaciones de Agentes¶
Antes de automatizar las evaluaciones de agentes, define objetivos claros y criterios de éxito:
- Define el Éxito: ¿Qué constituye un resultado exitoso para tu agente?
- Identifica Tareas Críticas: ¿Cuáles son las tareas esenciales que tu agente debe lograr?
- Elige Métricas Relevantes: ¿Qué métricas rastrearás para medir el rendimiento?
Estas consideraciones guiarán la creación de escenarios de evaluación y permitirán un monitoreo efectivo del comportamiento del agente en despliegues del mundo real.
¿Qué Evaluar?¶
Para cerrar la brecha entre una prueba de concepto y un agente de IA listo para producción, un marco de evaluación robusto y automatizado es esencial. A diferencia de evaluar modelos generativos, donde el enfoque está principalmente en la salida final, la evaluación de agentes requiere una comprensión más profunda del proceso de toma de decisiones. La evaluación de agentes se puede dividir en dos componentes:
- Evaluación de Trayectoria y Uso de Herramientas: Analizar los pasos que un agente toma para alcanzar una solución, incluyendo su elección de herramientas, estrategias y la eficiencia de su enfoque.
- Evaluación de la Respuesta Final: Evaluar la calidad, relevancia y corrección de la salida final del agente.
La trayectoria es solo una lista de pasos que el agente tomó antes de regresar al usuario. Podemos comparar eso con la lista de pasos que esperamos que el agente haya tomado.
Evaluación de trayectoria y uso de herramientas¶
Antes de responder a un usuario, un agente típicamente realiza una serie de acciones, a las que nos referimos como una 'trayectoria'. Podría comparar la entrada del usuario con el historial de sesión para desambiguar un término, o buscar un documento de política, buscar en una base de conocimientos o invocar una API para guardar un ticket. Llamamos a esto una 'trayectoria' de acciones. Evaluar el rendimiento de un agente requiere comparar su trayectoria real con una esperada, o ideal. Esta comparación puede revelar errores e ineficiencias en el proceso del agente. La trayectoria esperada representa la verdad fundamental -- la lista de pasos que anticipamos que el agente debería tomar.
Por ejemplo:
# La evaluación de trayectoria comparará
expected_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
actual_steps = ["determine_intent", "use_tool", "review_results", "report_generation"]
ADK proporciona métricas de evaluación de uso de herramientas tanto basadas en verdad fundamental como basadas en rúbricas. Para seleccionar la métrica apropiada para los requisitos y objetivos específicos de tu agente, consulta nuestras recomendaciones.
Cómo Funciona la Evaluación con el ADK¶
El ADK ofrece dos métodos para evaluar el rendimiento del agente contra conjuntos de datos predefinidos y criterios de evaluación. Aunque conceptualmente similares, difieren en la cantidad de datos que pueden procesar, lo que típicamente dicta el caso de uso apropiado para cada uno.
Primer enfoque: Usar un archivo de prueba¶
Este enfoque implica crear archivos de prueba individuales, cada uno representando una única y simple interacción agente-modelo (una sesión). Es más efectivo durante el desarrollo activo del agente, sirviendo como una forma de prueba unitaria. Estas pruebas están diseñadas para ejecución rápida y deben enfocarse en complejidad de sesión simple. Cada archivo de prueba contiene una única sesión, que puede consistir en múltiples turnos. Un turno representa una única interacción entre el usuario y el agente. Cada turno incluye
User Content: La consulta emitida por el usuario.Expected Intermediate Tool Use Trajectory: Las llamadas de herramientas que esperamos que el agente haga para responder correctamente a la consulta del usuario.Expected Intermediate Agent Responses: Estas son las respuestas en lenguaje natural que el agente (o sub-agentes) genera mientras se mueve hacia generar una respuesta final. Estas respuestas en lenguaje natural son generalmente un artefacto de un sistema multi-agente, donde tu agente raíz depende de sub-agentes para lograr un objetivo. Estas respuestas intermedias, pueden o no ser de interés para el usuario final, pero para un desarrollador/propietario del sistema, son de importancia crítica, ya que te dan la confianza de que el agente pasó por el camino correcto para generar la respuesta final.Final Response: La respuesta final esperada del agente.
Puedes darle al archivo cualquier nombre, por ejemplo evaluation.test.json. El marco solo verifica el sufijo .test.json, y la parte precedente del nombre del archivo no está restringida. Los archivos de prueba están respaldados por un modelo de datos Pydantic formal. Los dos archivos de esquema clave son
Eval Set y
Eval Case.
Aquí hay un archivo de prueba con algunos ejemplos:
(Nota: Los comentarios están incluidos con fines explicativos y deben eliminarse para que el JSON sea válido.)
# Nota que algunos campos se eliminan por el bien de hacer este documento legible.
{
"eval_set_id": "home_automation_agent_light_on_off_set",
"name": "",
"description": "This is an eval set that is used for unit testing `x` behavior of the Agent",
"eval_cases": [
{
"eval_id": "eval_case_id",
"conversation": [
{
"invocation_id": "b7982664-0ab6-47cc-ab13-326656afdf75", # Identificador único para la invocación.
"user_content": { # Contenido proporcionado por el usuario en esta invocación. Esta es la consulta.
"parts": [
{
"text": "Turn off device_2 in the Bedroom."
}
],
"role": "user"
},
"final_response": { # Respuesta final del agente que actúa como referencia de punto de referencia.
"parts": [
{
"text": "I have set the device_2 status to off."
}
],
"role": "model"
},
"intermediate_data": {
"tool_uses": [ # Trayectoria de uso de herramientas en orden cronológico.
{
"args": {
"location": "Bedroom",
"device_id": "device_2",
"status": "OFF"
},
"name": "set_device_info"
}
],
"intermediate_responses": [] # Cualquier respuesta intermedia de sub-agentes.
}
}
],
"session_input": { # Entrada de sesión inicial.
"app_name": "home_automation_agent",
"user_id": "test_user",
"state": {}
}
}
]
}
Los archivos de prueba se pueden organizar en carpetas. Opcionalmente, una carpeta también puede incluir un archivo test_config.json que especifica los criterios de evaluación.
¿Cómo migrar archivos de prueba que no están respaldados por el esquema Pydantic?¶
NOTA: Si tus archivos de prueba no se adhieren al archivo de esquema EvalSet, entonces esta sección es relevante para ti.
Por favor, usa AgentEvaluator.migrate_eval_data_to_new_schema para migrar tus
archivos *.test.json existentes al esquema respaldado por Pydantic.
La utilidad toma tu archivo de datos de prueba actual y un archivo de sesión inicial opcional, y genera un único archivo json de salida con datos serializados en el nuevo formato. Dado que el nuevo esquema es más cohesivo, tanto el archivo de datos de prueba antiguo como el archivo de sesión inicial pueden ser ignorados (o eliminados).
Segundo enfoque: Usar un Archivo Evalset¶
El enfoque evalset utiliza un conjunto de datos dedicado llamado "evalset" para evaluar interacciones agente-modelo. Similar a un archivo de prueba, el evalset contiene interacciones de ejemplo. Sin embargo, un evalset puede contener múltiples sesiones potencialmente largas, haciéndolo ideal para simular conversaciones complejas de múltiples turnos. Debido a su capacidad para representar sesiones complejas, el evalset es adecuado para pruebas de integración. Estas pruebas se ejecutan típicamente con menos frecuencia que las pruebas unitarias debido a su naturaleza más extensa.
Un archivo evalset contiene múltiples "evals", cada uno representando una sesión distinta. Cada eval consiste en uno o más "turnos", que incluyen la consulta del usuario, el uso esperado de herramientas, las respuestas intermedias esperadas del agente y una respuesta de referencia. Estos campos tienen el mismo significado que tienen en el enfoque de archivo de prueba. Alternativamente, un eval puede definir un escenario de conversación que se usa para simular dinámicamente una interacción del usuario con el agente. Cada eval se identifica por un nombre único. Además, cada eval incluye un estado de sesión inicial asociado.
Crear evalsets manualmente puede ser complejo, por lo tanto se proporcionan herramientas de UI para ayudar a capturar sesiones relevantes y convertirlas fácilmente en evals dentro de tu evalset. Aprende más sobre el uso de la UI web para evaluación a continuación. Aquí hay un ejemplo de evalset que contiene dos sesiones. Los archivos de eval set están respaldados por un modelo de datos Pydantic formal. Los dos archivos de esquema clave son Eval Set y Eval Case.
Warning
Este método de evaluación evalset requiere el uso de un servicio de pago, Vertex Gen AI Evaluation Service API.
(Nota: Los comentarios están incluidos con fines explicativos y deben eliminarse para que el JSON sea válido.)
# Nota que algunos campos se eliminan por el bien de hacer este documento legible.
{
"eval_set_id": "eval_set_example_with_multiple_sessions",
"name": "Eval set with multiple sessions",
"description": "This eval set is an example that shows that an eval set can have more than one session.",
"eval_cases": [
{
"eval_id": "session_01",
"conversation": [
{
"invocation_id": "e-0067f6c4-ac27-4f24-81d7-3ab994c28768",
"user_content": {
"parts": [
{
"text": "What can you do?"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "I can roll dice of different sizes and check if numbers are prime."
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [],
"intermediate_responses": []
}
}
],
"session_input": {
"app_name": "hello_world",
"user_id": "user",
"state": {}
}
},
{
"eval_id": "session_02",
"conversation": [
{
"invocation_id": "e-92d34c6d-0a1b-452a-ba90-33af2838647a",
"user_content": {
"parts": [
{
"text": "Roll a 19 sided dice"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "I rolled a 17."
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [],
"intermediate_responses": []
}
},
{
"invocation_id": "e-bf8549a1-2a61-4ecc-a4ee-4efbbf25a8ea",
"user_content": {
"parts": [
{
"text": "Roll a 10 sided dice twice and then check if 9 is a prime or not"
}
],
"role": "user"
},
"final_response": {
"parts": [
{
"text": "I got 4 and 7 from the dice roll, and 9 is not a prime number.\n"
}
],
"role": null
},
"intermediate_data": {
"tool_uses": [
{
"id": "adk-1a3f5a01-1782-4530-949f-07cf53fc6f05",
"args": {
"sides": 10
},
"name": "roll_die"
},
{
"id": "adk-52fc3269-caaf-41c3-833d-511e454c7058",
"args": {
"sides": 10
},
"name": "roll_die"
},
{
"id": "adk-5274768e-9ec5-4915-b6cf-f5d7f0387056",
"args": {
"nums": [
9
]
},
"name": "check_prime"
}
],
"intermediate_responses": [
[
"data_processing_agent",
[
{
"text": "I have rolled a 10 sided die twice. The first roll is 5 and the second roll is 3.\n"
}
]
]
]
}
}
],
"session_input": {
"app_name": "hello_world",
"user_id": "user",
"state": {}
}
}
]
}
¿Cómo migrar archivos de eval set que no están respaldados por el esquema Pydantic?¶
NOTA: Si tus archivos de eval set no se adhieren al archivo de esquema EvalSet, entonces esta sección es relevante para ti.
Basado en quién mantiene los datos del eval set, hay dos rutas:
-
Datos de eval set mantenidos por ADK UI Si usas ADK UI para mantener tus datos de Eval set entonces no se necesita acción de tu parte.
-
Los datos de eval set se desarrollan y mantienen manualmente y se usan en ADK eval CLI Una herramienta de migración está en proceso, hasta entonces el comando ADK eval CLI continuará soportando datos en el formato antiguo.
Criterios de Evaluación¶
ADK proporciona varios criterios integrados para evaluar el rendimiento del agente, que van desde la coincidencia de trayectoria de herramientas hasta la evaluación de calidad de respuesta basada en LLM. Para una lista detallada de criterios disponibles y orientación sobre cuándo usarlos, consulta Criterios de Evaluación.
Aquí hay un resumen de todos los criterios disponibles:
- tool_trajectory_avg_score: Coincidencia exacta de la trayectoria de llamadas de herramientas.
- response_match_score: Similitud ROUGE-1 con la respuesta de referencia.
- final_response_match_v2: Coincidencia semántica juzgada por LLM con una respuesta de referencia.
- rubric_based_final_response_quality_v1: Calidad de respuesta final juzgada por LLM basada en rúbricas personalizadas.
- rubric_based_tool_use_quality_v1: Calidad de uso de herramientas juzgada por LLM basada en rúbricas personalizadas.
- hallucinations_v1: Fundamentación juzgada por LLM de la respuesta del agente contra el contexto.
- safety_v1: Seguridad/inocuidad de la respuesta del agente.
Si no se proporcionan criterios de evaluación, se utiliza la siguiente configuración predeterminada:
tool_trajectory_avg_score: Por defecto es 1.0, requiriendo una coincidencia del 100% en la trayectoria de uso de herramientas.response_match_score: Por defecto es 0.8, permitiendo un pequeño margen de error en las respuestas en lenguaje natural del agente.
Aquí hay un ejemplo de un archivo test_config.json que especifica criterios de evaluación personalizados:
Recomendaciones sobre Criterios¶
Elige criterios basados en tus objetivos de evaluación:
- Habilitar pruebas en pipelines de CI/CD o pruebas de regresión: Usa
tool_trajectory_avg_scoreyresponse_match_score. Estos criterios son rápidos, predecibles y adecuados para verificaciones automatizadas frecuentes. - Evaluar respuestas de referencia confiables: Usa
final_response_match_v2para evaluar equivalencia semántica. Esta verificación basada en LLM es más flexible que la coincidencia exacta y captura mejor si la respuesta del agente significa lo mismo que la respuesta de referencia. - Evaluar calidad de respuesta sin una respuesta de referencia: Usa
rubric_based_final_response_quality_v1. Esto es útil cuando no tienes una referencia confiable, pero puedes definir atributos de una buena respuesta (por ejemplo, "La respuesta es concisa," "La respuesta tiene un tono útil"). - Evaluar la corrección del uso de herramientas: Usa
rubric_based_tool_use_quality_v1. Esto te permite validar el proceso de razonamiento del agente verificando, por ejemplo, que se llamó a una herramienta específica o que las herramientas se llamaron en el orden correcto (por ejemplo, "La herramienta A debe ser llamada antes de la herramienta B"). - Verificar si las respuestas están fundamentadas en el contexto: Usa
hallucinations_v1para detectar si el agente hace afirmaciones que no están respaldadas por o son contradictorias a la información disponible para él (por ejemplo, salidas de herramientas). - Verificar contenido dañino: Usa
safety_v1para asegurar que las respuestas del agente sean seguras y no violen las políticas de seguridad.
Además, los criterios que requieren información sobre el uso esperado de herramientas del agente
y/o respuestas no son compatibles en combinación con
Simulación de Usuario.
Actualmente, solo los criterios hallucinations_v1 y safety_v1 soportan tales evals.
Simulación de Usuario¶
Al evaluar agentes conversacionales, no siempre es práctico usar un conjunto fijo de prompts de usuario, ya que la conversación puede proceder de maneras inesperadas. Por ejemplo, si el agente necesita que el usuario proporcione dos valores para realizar una tarea, puede pedir esos valores uno a la vez o ambos a la vez. Para resolver este problema, ADK te permite probar el comportamiento del agente en un escenario de conversación específico con prompts de usuario que son dinámicamente generados por un modelo de IA. Para detalles sobre cómo configurar un eval con simulación de usuario, consulta Simulación de Usuario.
Cómo Ejecutar la Evaluación con el ADK¶
Como desarrollador, puedes evaluar tus agentes usando el ADK de las siguientes maneras:
- UI basada en web (
adk web): Evalúa agentes interactivamente a través de una interfaz basada en web. - Programáticamente (
pytest): Integra la evaluación en tu pipeline de pruebas usandopytesty archivos de prueba. - Interfaz de Línea de Comandos (
adk eval): Ejecuta evaluaciones en un archivo de conjunto de evaluación existente directamente desde la línea de comandos.
1. adk web - Ejecutar Evaluaciones a través de la UI Web¶
La UI web proporciona una forma interactiva de evaluar agentes, generar conjuntos de datos de evaluación e inspeccionar el comportamiento del agente en detalle.
Paso 1: Crear y Guardar un Caso de Prueba¶
- Inicia el servidor web ejecutando:
adk web <path_to_your_agents_folder> - En la interfaz web, selecciona un agente e interactúa con él para crear una sesión.
- Navega a la pestaña Eval en el lado derecho de la interfaz.
- Crea un nuevo eval set o selecciona uno existente.
- Haz clic en "Add current session" para guardar la conversación como un nuevo caso de evaluación.
Paso 2: Ver y Editar tu Caso de Prueba¶
Una vez que se guarda un caso, puedes hacer clic en su ID en la lista para inspeccionarlo. Para hacer cambios, haz clic en el icono Edit current eval case (lápiz). Esta vista interactiva te permite:
- Modificar respuestas de texto del agente para refinar escenarios de prueba.
- Eliminar mensajes individuales del agente de la conversación.
- Eliminar el caso de evaluación completo si ya no es necesario.
Paso 3: Ejecutar la Evaluación con Métricas Personalizadas¶
- Selecciona uno o más casos de prueba de tu evalset.
- Haz clic en Run Evaluation. Aparecerá un diálogo de EVALUATION METRIC.
- En el diálogo, usa los deslizadores para configurar los umbrales para:
- Tool trajectory avg score
- Response match score
- Haz clic en Start para ejecutar la evaluación usando tus criterios personalizados. El historial de evaluación registrará las métricas usadas para cada ejecución.
Paso 4: Analizar Resultados¶
Después de que se complete la ejecución, puedes analizar los resultados:
- Analizar Fallos de Ejecución: Haz clic en cualquier resultado de Pass o Fail. Para fallos, puedes pasar el cursor sobre la etiqueta
Failpara ver una comparación lado a lado de la Salida Real vs. Esperada y las puntuaciones que causaron el fallo.
Depuración con la Vista de Traza¶
La UI web de ADK incluye una poderosa pestaña Trace para depurar el comportamiento del agente. Esta función está disponible para cualquier sesión del agente, no solo durante la evaluación.
La pestaña Trace proporciona una forma detallada e interactiva de inspeccionar el flujo de ejecución de tu agente. Las trazas se agrupan automáticamente por mensaje de usuario, facilitando el seguimiento de la cadena de eventos.
Cada fila de traza es interactiva:
- Pasar el cursor sobre una fila de traza resalta el mensaje correspondiente en la ventana de chat.
- Hacer clic en una fila de traza abre un panel de inspección detallado con cuatro pestañas:
- Event: Los datos de evento sin procesar.
- Request: La solicitud enviada al modelo.
- Response: La respuesta recibida del modelo.
- Graph: Una representación visual de las llamadas de herramientas y el flujo de lógica del agente.
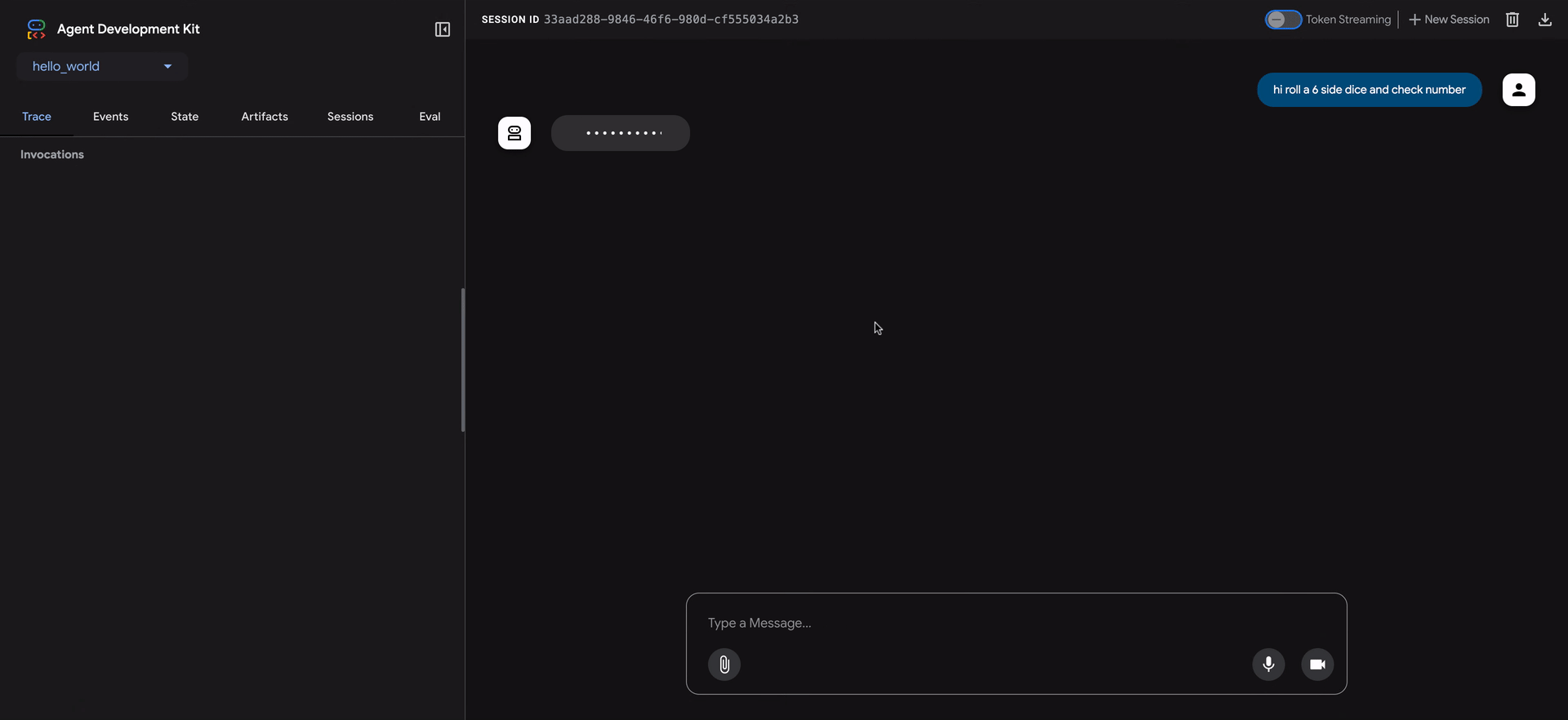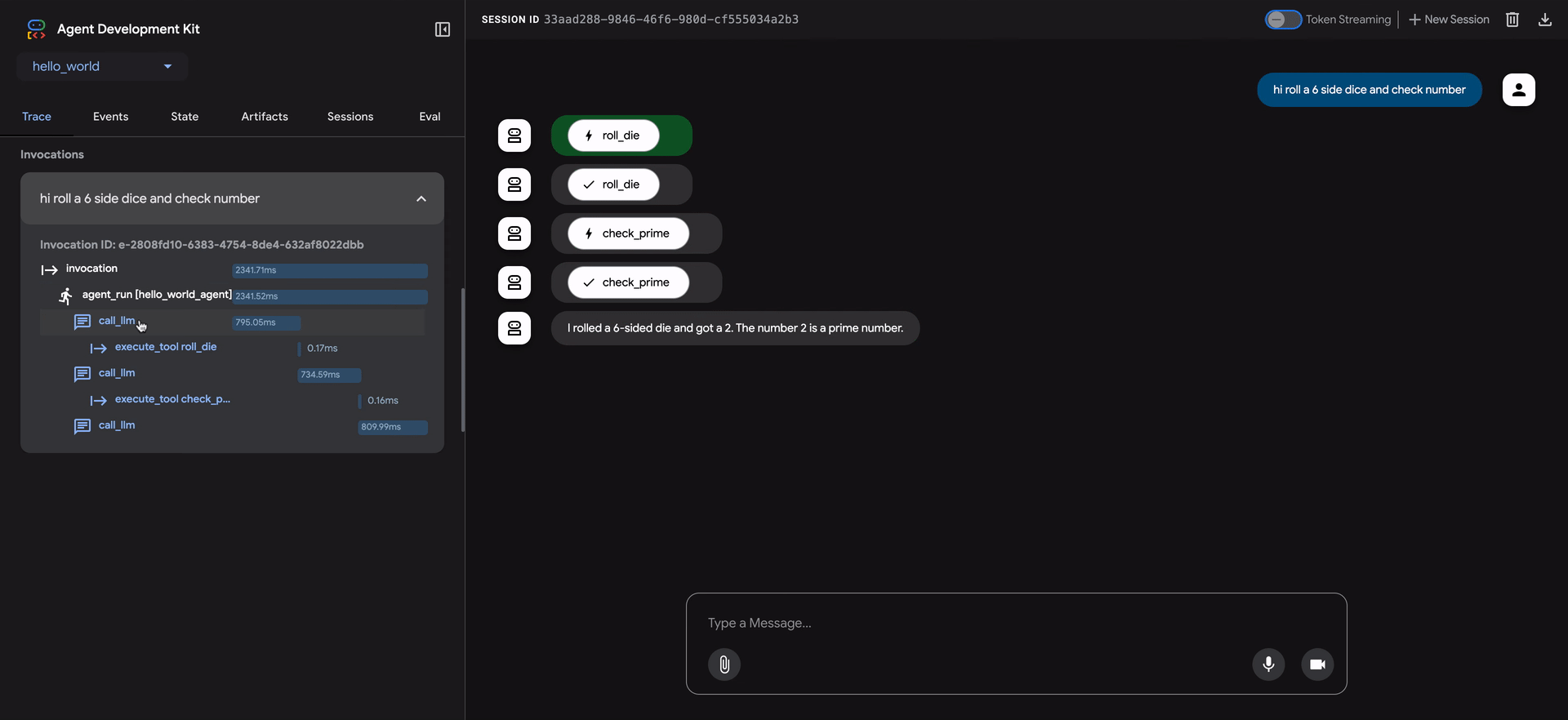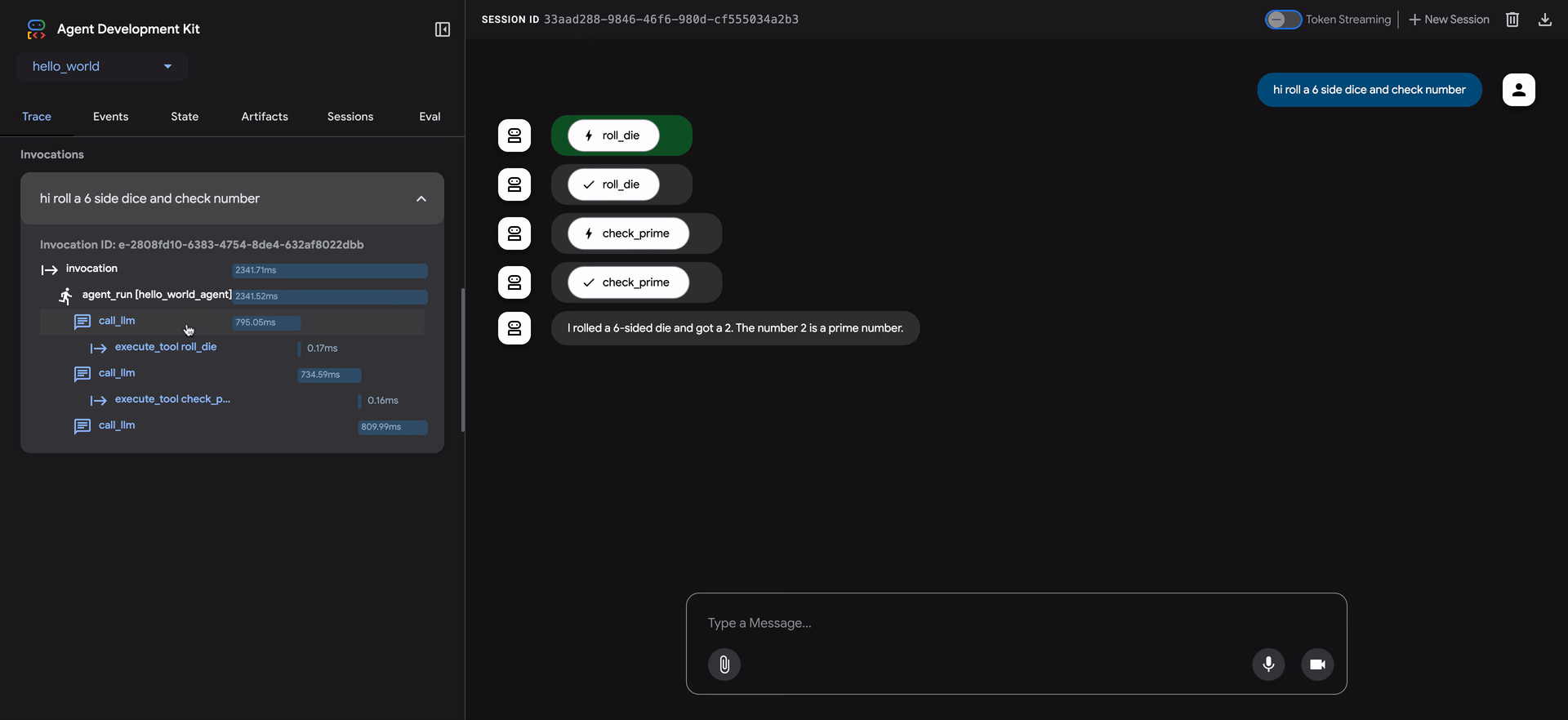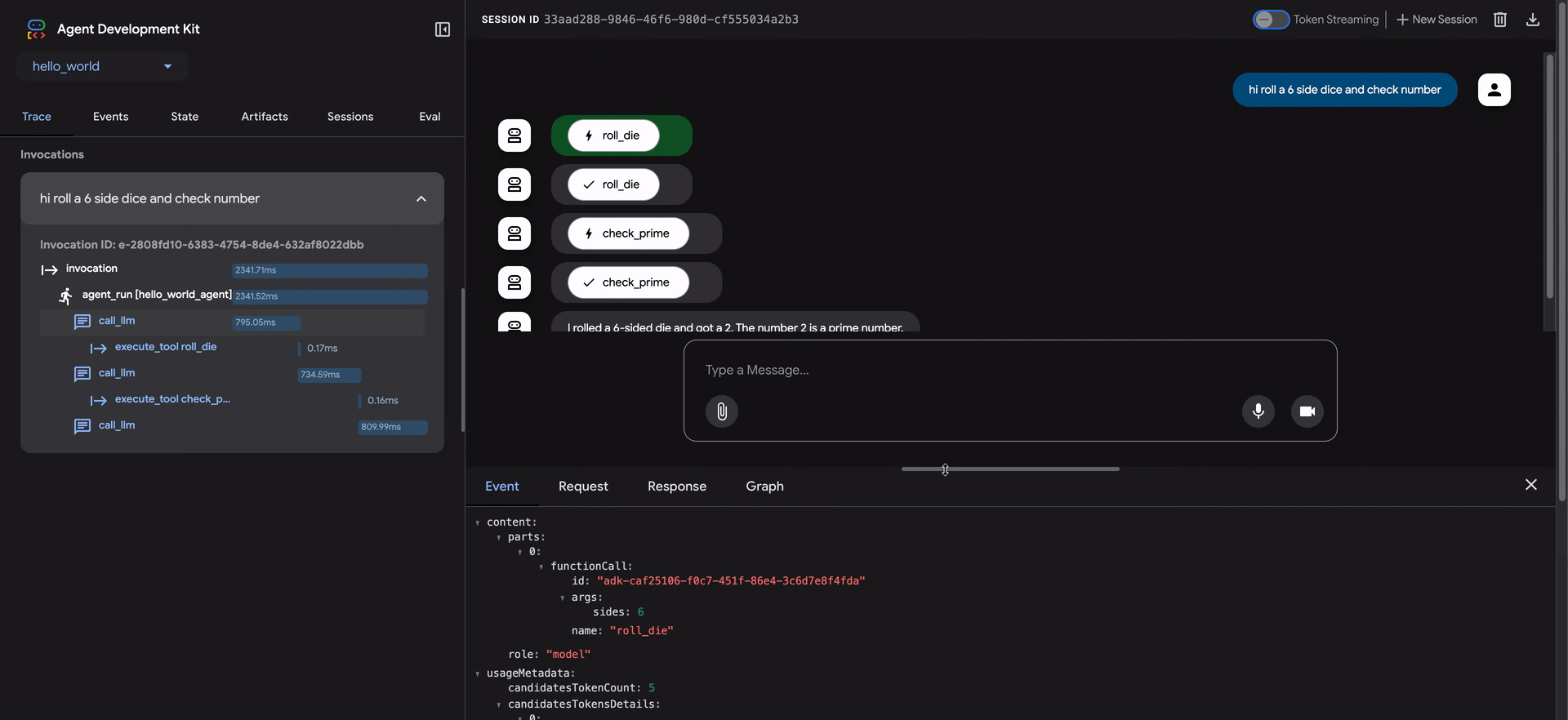
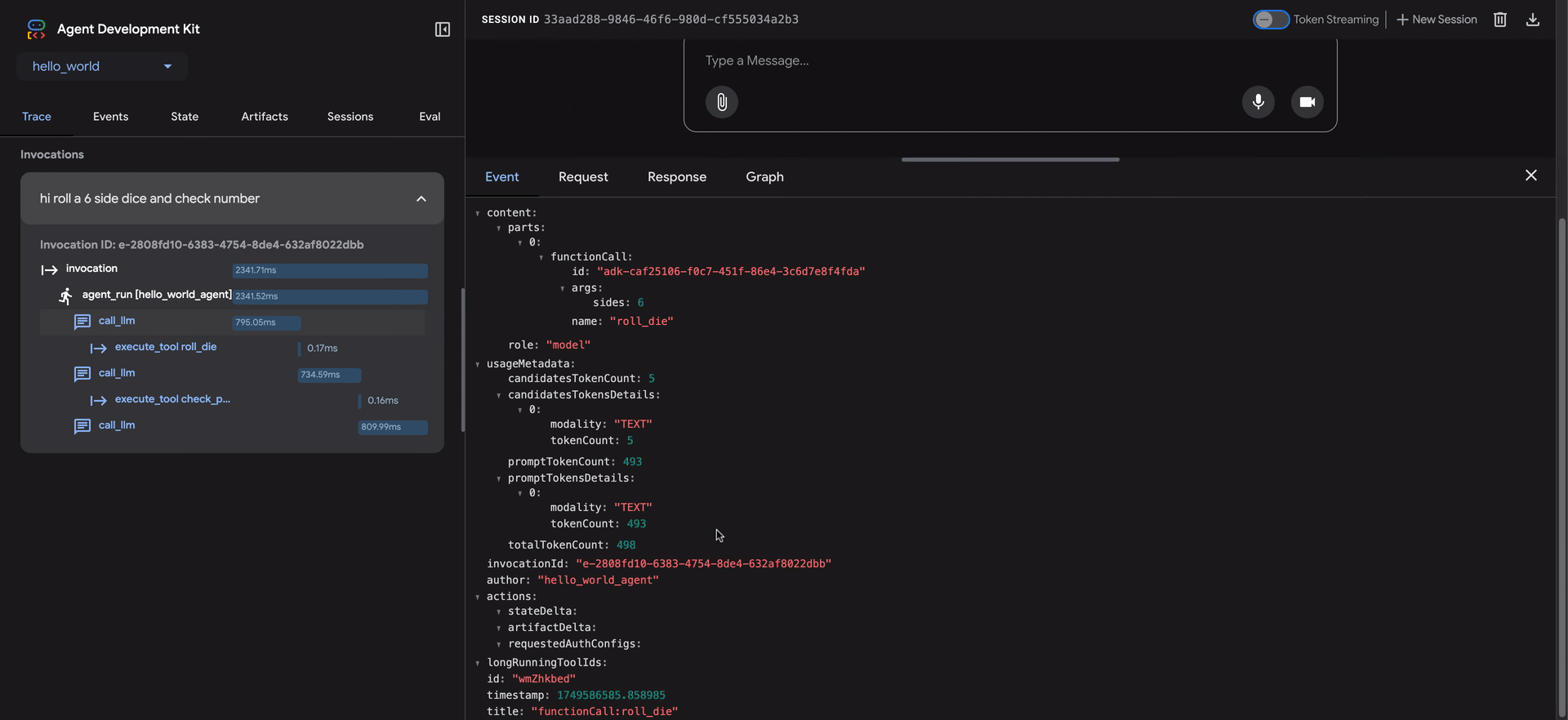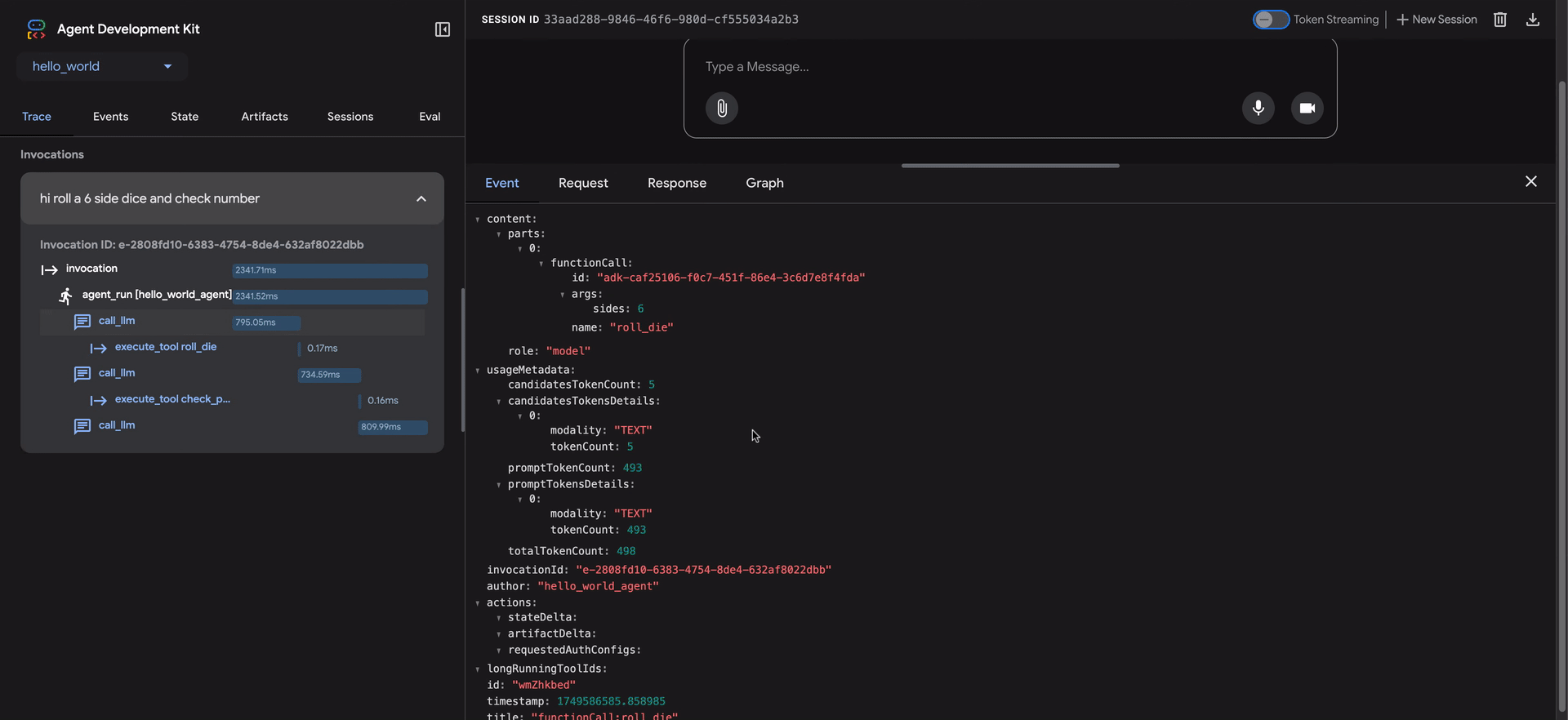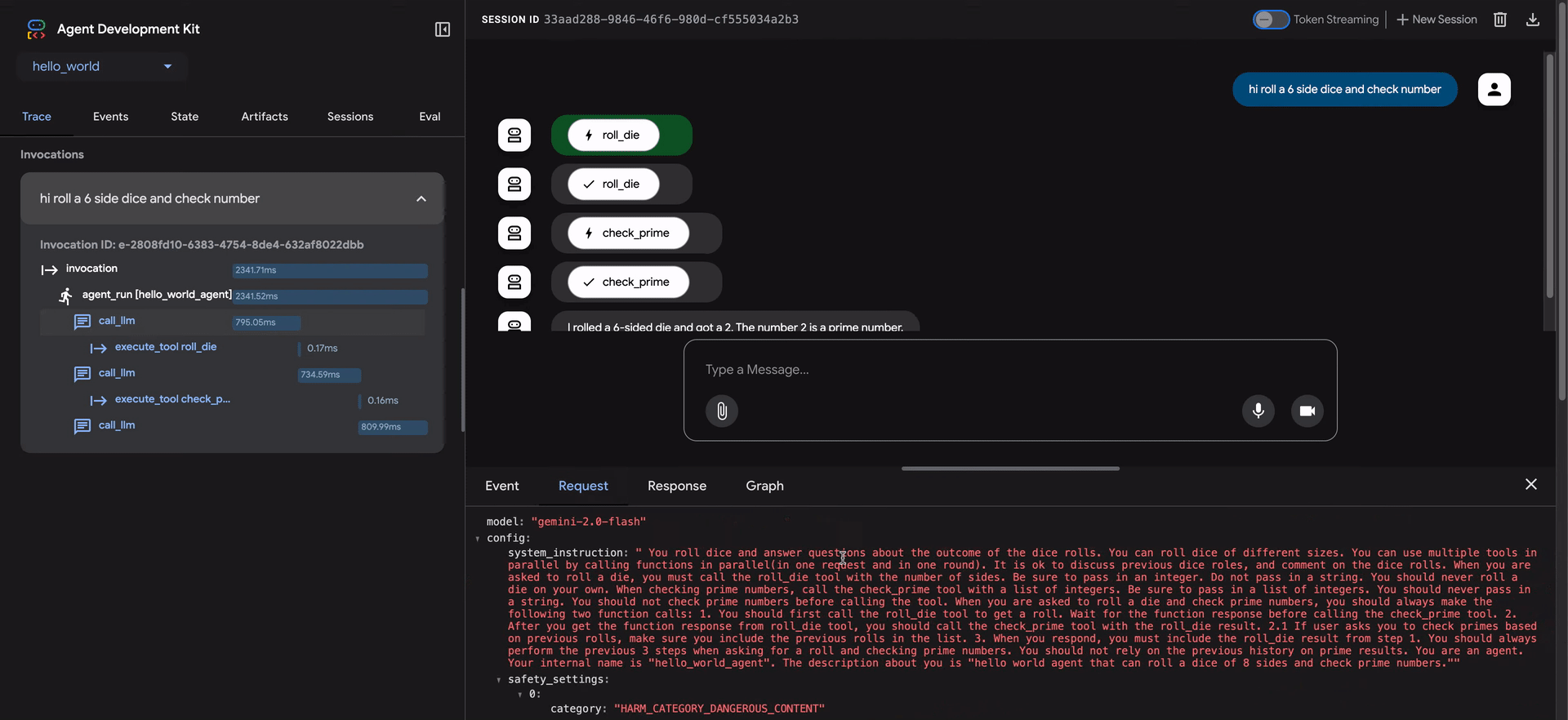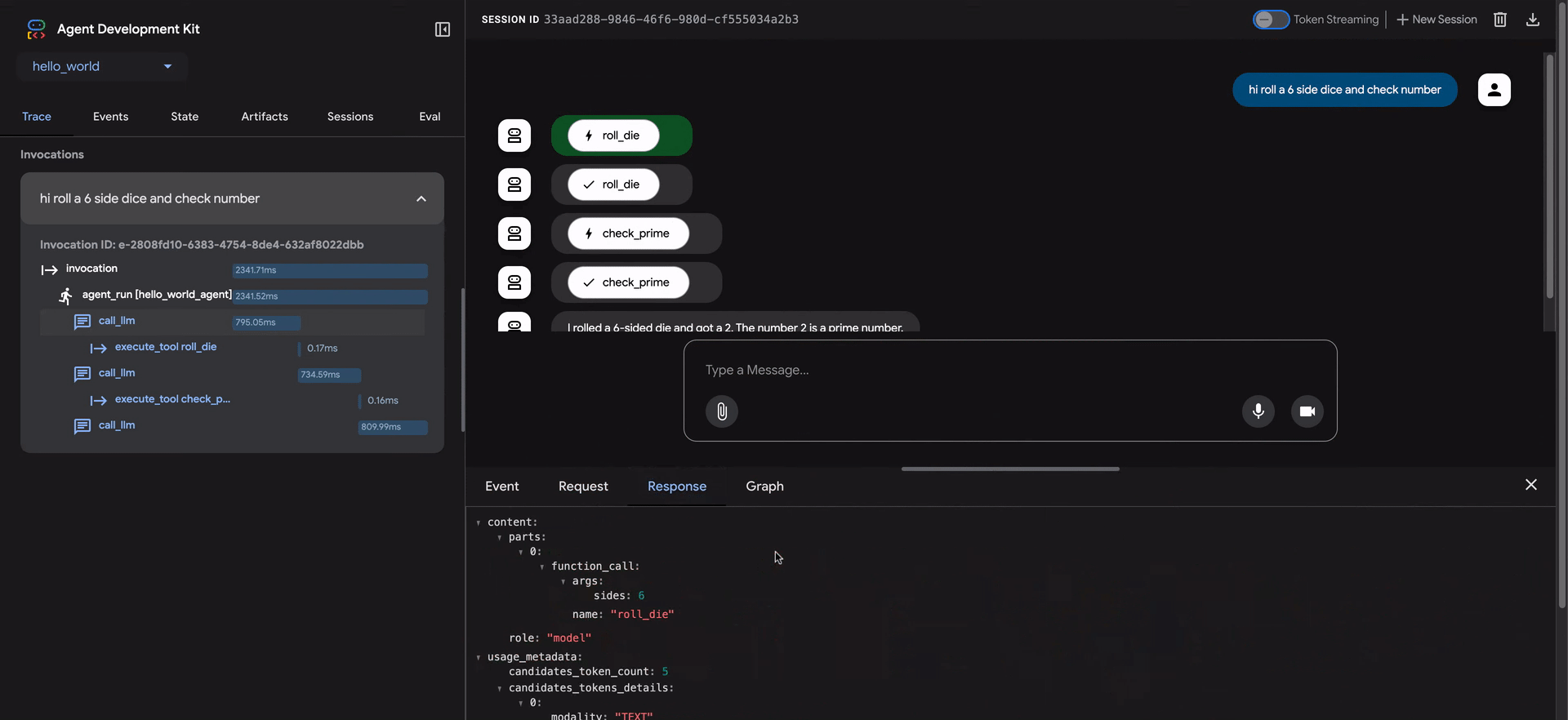
Las filas azules en la vista de traza indican que se generó un evento de esa interacción. Hacer clic en estas filas azules abrirá el panel de detalles de evento inferior, proporcionando información más profunda sobre el flujo de ejecución del agente.
2. pytest - Ejecutar Pruebas Programáticamente¶
También puedes usar pytest para ejecutar archivos de prueba como parte de tus pruebas de integración.
Comando de Ejemplo¶
Código de Prueba de Ejemplo¶
Aquí hay un ejemplo de un caso de prueba pytest que ejecuta un único archivo de prueba:
from google.adk.evaluation.agent_evaluator import AgentEvaluator
import pytest
@pytest.mark.asyncio
async def test_with_single_test_file():
"""Test the agent's basic ability via a session file."""
# Prueba la capacidad básica del agente a través de un archivo de sesión.
await AgentEvaluator.evaluate(
agent_module="home_automation_agent",
eval_dataset_file_path_or_dir="tests/integration/fixture/home_automation_agent/simple_test.test.json",
)
Este enfoque te permite integrar evaluaciones de agentes en tus pipelines de CI/CD o conjuntos de pruebas más grandes. Si deseas especificar el estado de sesión inicial para tus pruebas, puedes hacerlo almacenando los detalles de la sesión en un archivo y pasándolo al método AgentEvaluator.evaluate.
3. adk eval - Ejecutar Evaluaciones a través del CLI¶
También puedes ejecutar la evaluación de un archivo de eval set a través de la interfaz de línea de comandos (CLI). Esto ejecuta la misma evaluación que se ejecuta en la UI, pero ayuda con la automatación, es decir, puedes agregar este comando como parte de tu proceso regular de generación y verificación de compilación.
Aquí está el comando:
adk eval \
<AGENT_MODULE_FILE_PATH> \
<EVAL_SET_FILE_PATH> \
[--config_file_path=<PATH_TO_TEST_JSON_CONFIG_FILE>] \
[--print_detailed_results]
Por ejemplo:
adk eval \
samples_for_testing/hello_world \
samples_for_testing/hello_world/hello_world_eval_set_001.evalset.json
Aquí están los detalles para cada argumento de línea de comandos:
AGENT_MODULE_FILE_PATH: La ruta al archivo__init__.pyque contiene un módulo con el nombre "agent". El módulo "agent" contiene unroot_agent.EVAL_SET_FILE_PATH: La ruta a los archivos de evaluaciones. Puedes especificar una o más rutas de archivos de eval set. Para cada archivo, todos los evals se ejecutarán por defecto. Si deseas ejecutar solo evals específicos de un eval set, primero crea una lista separada por comas de nombres de eval y luego agrégala como un sufijo al nombre del archivo de eval set, demarcado por dos puntos:.- Por ejemplo:
sample_eval_set_file.json:eval_1,eval_2,eval_3
Esto solo ejecutará eval_1, eval_2 y eval_3 de sample_eval_set_file.json CONFIG_FILE_PATH: La ruta al archivo de configuración.PRINT_DETAILED_RESULTS: Imprime resultados detallados en la consola.